Estrutura de Dados
Nesta parte, serão apresentados duas estruturas baseadas em árvores e uma implementação de set do GNU C++.
GNU C++ Policy-Based Sets
O compilador GNU g++ também suporta algumas estruturas de dados que não fazem parte da biblioteca padrão do C++. Essas estruturas são chamadas de estruturas de dados baseadas em políticas (Policy-Based Data Structures - PBDS). Para usar essas estruturas é necessário incluir o seguinte código:
Alternativamente, pode-se simplificar o código anterior da seguinte forma:
Após isso, é possível definir um conjunto ordenado indexado (entre as disponíveis, essa é a principal estrutura usada em competições de programação). Esta estrutura é como o set, mas com a possibilidade de acessar os elementos de acordo com a sua posição (índice), como em um array. O código abaixo, define um conjunto ordenado indexado usando template.
Veja alguns exemplos de uso da definição anterior:
Além das operações comuns do set (insert, erase, size, clear, find, begin, end), ainda existem duas funções muito úteis e que justificam o uso do PBDS:
find_by_order(k): retorna um iterador para o \(k\)-ésimo menor elemento (contando a partir de zero) do conjunto em tempo \(O(\log n)\);order_of_key(x): retorna ao número de itens estritamente menores que oxem tempo \(O(\log n)\).
Veja um exemplo completo de utilização do PBDS (Fonte: pbds.cpp):
Complemente sua leitura e seu conhecimento:
Fenwick (Binary Indexed) Tree
Considere o seguinte problema:
Você possui \(n\) caixas com bolinhas de gude e deseja:
-
Adicionar bolinhas de gude a caixa \(i\);
-
Saber a quantidade de bolinhas de gude que existem da caixa \(a\) até a caixa \(b\), ou seja, a soma das bolinhas nas caixas \([a, a+1, a+2, \dots, b]\).
O objetivo é implementar essas duas operações de forma eficiente. Esse problema é conhecido como Range Sum Queries (RSQ).
Uma abordagem ingênua, mostrada abaixo, possui \(O(1)\) para a operação 1 e \(O(n)\) para a 2. Se forem feitas \(m\) operações 2, no pior caso, a complexidade de tempo será \(O(n*m)\).
Para responder range sum queries em sequências dinâmicas com melhor complexidade é preciso usar estruturas mais sofisticadas, que permitam a atualização das somas pré-computadas de forma eficiente. Uma destas estruturas é a Binary Indexed Tree (BIT ou Fenwick Tree), proposta por Peter M. Fenwick em 1994. Usando BIT, ambas as operações são feitas em \(O(\log n)\).
A ideia da BIT é que, assim como um número pode ser representado como uma soma de algumas potências de dois, uma soma cumulativa pode ser representada como uma soma de algumas somas cumulativas parciais. Para isso, cada índice \(i\) no array de soma cumulativa é responsável pela soma cumulativa do índice \(i\) até \((i - (1<<r) + 1)\), onde \(r\) representa a posição do último bit 1 da representação binária de \(i\) (o \(p(i) = (1<<r)\) também pode ser visto como a maior potência de \(2\) que divide \(i\)). Por exemplo, o índice \(15_{10} = 1111_2\) ficará responsável pela soma do intervalo \(15 - (1<<0) + 1 = 15 - 1 + 1\) a \(15\). Já o índice \(12_{10} = 1100_2\) ficará responsável pela soma do intervalo \(12 - (1<<3) + 1 = 12 - 8 + 1 = 9\) a \(12\), e assim por diante. A tabela abaixo mostra a responsabilidade dos índices 1 a 16.
| Índice | Responsável pela soma parcial do intervalo |
|---|---|
| 16 | [01, 16] |
| 15 | [15, 15] |
| 14 | [13, 14] |
| 13 | [13, 13] |
| 12 | [09, 12] |
| 11 | [11, 11] |
| 10 | [09, 10] |
| 09 | [09, 09] |
| 08 | [01, 08] |
| 07 | [07, 07] |
| 06 | [05, 06] |
| 05 | [05, 05] |
| 04 | [01, 04] |
| 03 | [03, 03] |
| 02 | [01, 02] |
| 01 | [01, 01] |
Perceba que todo índice ímpar fica responsável por um intervalo de tamanho 1 (porquê?). Já os índices \(i\) que são potência de 2, ficam responsáveis pelo intervalo \([1, i]\).
Tipicamente, a Fenwick Tree é implementada usando um array (vector), digamos ft, de modo que:
Assim, cada posição i contém a soma dos valores de um intervalo do array original cujo comprimento é p(i) e que termina na posição i. Por exemplo, como p(6) = 2, ft[6] contém o valor de sum(5,6).
Considere o seguinte array original:
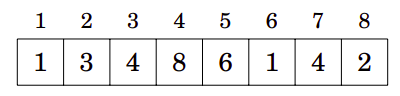
A Fenwick Tree correspondente é a seguinte:
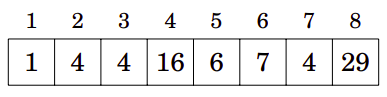
A figura abaixo mostra mais claramente como cada valor na BIT corresponde a um intervalo no array original:
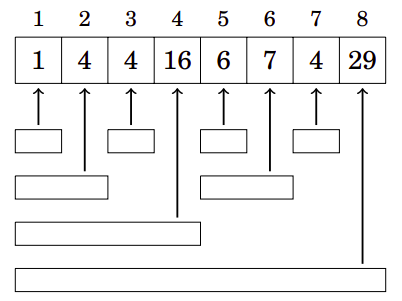
Usando uma BIT, qualquer valor de sum(1,i) pode ser calculado em tempo \(O(\log n)\), pois um intervalo \([1,i]\) sempre pode ser dividido em intervalos \(O(\log n)\) cujas somas são armazenadas na árvore. Por exemplo, o intervalo \([1,7]\) consiste nos seguintes intervalos:
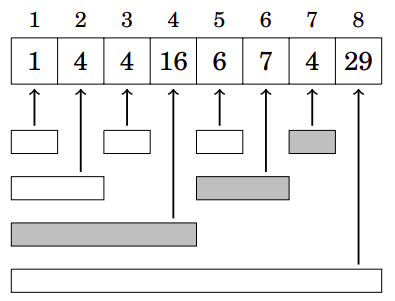
Assim, pode-se calcular a soma correspondente da seguinte forma:
Para calcular o valor de \(sum(a,b)\) onde \(a > 1\), pode-se usar o mesmo truque que usado na soma de prefixo:
Como pode-se calcular tanto \(sum(1, b)\) quanto \(sum(1, a−1)\) em tempo \(O(\log n)\), a complexidade de tempo total é \(O(\log n)\).
Além de calcular a soma parcial, também é possível/necessário atualizar o valor de uma determinada posição no array original. Após a atualização, alguns valores na BIT devem ser atualizados. Por exemplo, se o valor na posição 3 mudar, as somas dos seguintes intervalos mudam:
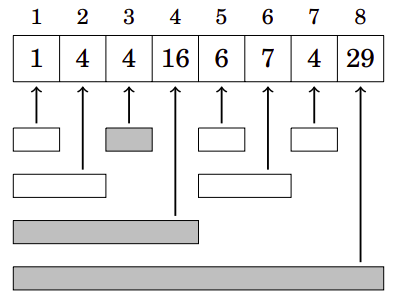
Como cada elemento do array pertence a \(O(\log n)\) intervalos na BIT, basta atualizar os \(O(\log n)\) valores na árvore.
Implementação
O primeiro passo é definir como calcular o valor de p(i), ou seja, a maior potência de \(2\) que divide \(i\). Este valor é conhecido como o bit menos significativo, abreviado lsb, da representação binária de \(i\). O função abaixo calcula esse valor:
Essa função possui complexidade \(O(\log n)\). Entretanto, usando manipulação de bits, pode-se encontrar esse valor de forma mais eficiente. Lembre-se que um número negativo é representado usando complemento de 2, ou seja, pega-se a representação binária de x, inverte-se os bits e adiciona 1 (ignorando o resto final). Por exemplo, considere x = 108 e que os valores são representados em 8 bits:
Observe que os bits mais significativos que o lsb são diferentes para x e -x, enquanto o lsb e os 0s seguintes são os mesmos. Portanto, x & −x dá a resposta desejada, ou seja: x & -x = 00000100. Com essa estratégia, pode-se calcular o valor de lsb, consequentemente, o valor de p(i) em \(O(1)\):
- Normalmente, essa função é feita como uma macro:
#define lsb(i) ((i) & -(i))
A funções a seguir calculam o valor de \(sum(1,i)\) e \(sum(a, b)\), respectivamente:
A seguinte função aumenta o valor do array na posição \(i\) em \(x\) (\(x\) pode ser positivo ou negativo):
Para construir a BIT a partir de um array original, uma primeira estratégia é iniciar o array ft com valor 0 em todas as posições. Em seguida, para cada posição \(i\), chama-se a função add passando o valor do array original como valor a ser incrementado, o que daria resultaria em \(O(n \log n)\) operações. Veja a função abaixo:
Entretanto, note que após atualizar o valor de ft[i], pode-se verificar se o "pai" de \(i\) é menor que \(N\) (tamanho do array). Se for, atualiza-se o "pai" também. Dessa forma, temos uma função com complexidade \(O(n)\).
Também é possível encontrar o menor índice \(i\) tal que soma acumulativa do intervalo \([1..i] \geq k\). Como as somas acumulativas dos valores estão ordenadas, pode-se usar a busca binária para encontrar tal índice. Basicamente, testa-se o índice do meio \(m = n / 2\) do intervalo inicial \([1..n]\) e verifica se sum(1, i) é menor que \(k\) ou não. Para cada valor de \(m\), tem-se \(O(\log n)\) operações, logo, essa função terá complexidade \(O(\log n \times \log n) = O(\log^2 n)\). O código abaixo ilustra tal função:
- \(2^{30} > 10^9\), normalmente é suficiente.
O código abaixo mostra uma implementação completa de uma BIT. Note que foi usado uma versão baseada em orientação à objetos, mas isso não é necessário.
Quando usar?
Para utilizar uma árvore de Fenwick para realizar a operação \(\odot\) em um intervalo de índices \([i,j]\) da sequência \(a_k\), é necessário que esta operação tenha duas propriedades:
-
Associatividade: para quaisquer \(x, y, z \in a_k\), deve valer que: \((x \odot y)\odot z = x \odot (y \odot z)\);
-
Invertibilidade: para qualquer \(x \in a_k\), deve existir um valor \(y\) tal que \(x\odot y = I\), onde \(I\) é o elemento neutro/identidade da operação \(\odot\).
Como exemplos de operações que têm ambas propriedades tem-se a adição e a multiplicação de racionais, a adição de matrizes e o ou exclusivo (xor).
Material complementar
- Binary Indexed Tree or Fenwick Tree (GeeksforGeeks)
- Fenwick Tree
- Binary Indexed Trees (Topcoder)
- Fenwick Tree (Binary Index Tree) - Quick Tutorial and Source Code Explanation
- Tutorial: Binary Indexed Tree (Fenwick Tree)
- Binary Indexed (Fenwick) Tree - VisuAlgo
Segment Tree
Segment tree (Árvore de Segmento ou SegTree) é outra estrutura de dados para lidar com problemas de consulta em intervalos. O que torna as SegTrees poderosas é sua capacidade de fazer atualização e consulta em intervalos com complexidade \(O(\log n)\), além do tipo da consulta ser bem abrangente. Entretanto, comparada a BIT, uma SegTree requer mais memória e é um pouco mais difícil de implementar.
A ideia da SegTree é a seguinte: cria-se uma árvore de forma que cada nó representa a informação que deseja-se saber a respeito de um segmento do vetor (por exemplo, a soma). Cada nó (exceto as folhas) possui dois filhos, um filho representa a metade esquerda do intervalo e o outro, a metade direita. Esse processo repete-se (recursivamente) até que os intervalos atinjam tamanho 1. Assim, considerando o Range Sum Queries (RSQ), o nó raíz da árvore armazena a soma de todo o array, ou seja, a soma do segmento \(a[0 \dots n-1]\). Em seguida, essa segmento é dividido em dois: o filho da esquerda fica responsável pelo calcular/armazenar a soma da metade da esquerda do segmento (ou seja, \(a[0 \dots n/2]\)) e o filho da direita responsável pela metade da direita do segmento (ou seja, \(a[n/2+1 \dots n-1]\)). Cada um desses nós é novamente dividido e calcula-se a soma de cada novo intervalo. Repete-se o processo até todos os segmentos atingirem tamanho 1. Nesse link você encontra uma demonstração visual de como a SegTree funciona.
Veja uma representação visual de uma SegTree para o array a = [1,3,−2,8,−7]:
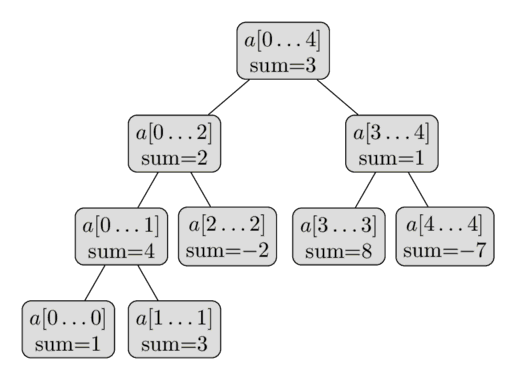
Note que o primeiro nível da árvore contém um único nó (a raiz), o segundo nível contém 2 nós, no terceiro contém 4, e assim por diante, até que o número de nós alcance \(n\). Portanto, o número de nós, no pior caso, pode ser estimado pela soma \(1+2+4+\cdots+2^{\lceil \log_2 n \rceil}=2^{ \lceil \log_2 n \rceil+1} < 4n\).
Consultas
Suponha que deseja-se fazer uma consulta (por exemplo, calcular a soma, valor mínimo/máximo, etc.) no intervalo \(l\) e \(r\), ou seja, deseja-se fazer um consulta no segmento \(a[l \dots r]\). Para isso, deve-se percorrer a árvore de segmentos e usar os valores pré-computados dos segmentos. Considere que a consulta esteja no vértice que cobre o segmento \(a[tl \dots tr]\). Existem três possibilidades:
-
O nó está fora do intervalo de interesse, ou seja,
tr < l || r < tl. Retorne um valor neutro que não afete a cunsulta (por exemplo, se a operação for a soma, retorne 0); -
O nó está completamente incluído no intervalos de interesse, ou seja,
tl >= l && tr <= r. Retorne a informação armazenada no nó; -
O nó está parcialmente contido no intervalo de interesse, ou seja,
(l <= tr && tr <= r) || (l <= tl && tl <= r). Então, a consulta continua nos nós filhos.
A figura abaixo ilustra esse processo para encontrar a soma do segmento \(a[2 \dots 4]\) para o array a = [1,3,−2,8,−7]. Os nós coloridos serão visitados e usa-se os valores pré-calculados dos nós verdes. Assim, o resultado será \(−2 + 1=−1\). O número de nós visitados é proporcional à altura da árvore, ou seja, \(O(\log n)\).
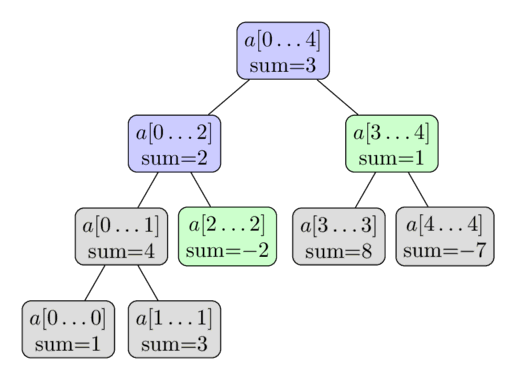
Atualizações
Fazer uma atualização no array original (por exemplo, fazer a[i] = x) implica que a SegTree também deve ter alguns nós atualizados, de modo que ela corresponda ao novo array modificado. Perceba que cada nível de uma SegTree forma uma partição do array. Portanto, um elemento a[i] apenas contribui para um segmento de cada nível. Assim, apenas \(O(\log n)\) nós necessitam ser atualizadas.
A atualização dos elementos pode ser facilmente implementada usando uma função recursiva. A função passa pelo nó atual da árvore e recursivamente chama a si mesma com um dos dois nós filhos (aquele que contém a[i] em seu segmento) e, em seguida, recalcula seu valor.
Considerando a SegTree do array a = [1,3,−2,8,−7], ao fazer a[2] = 3, os nós verdes são os nós visitados e atualizados.
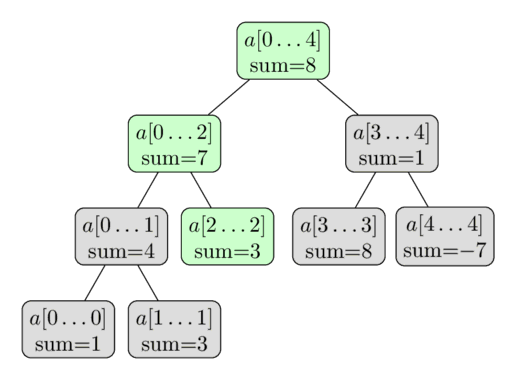
Implementação
A primeira função a ser analisada/implementada é a build, responsável por criar a SegTree. Assim como na BIT, aqui também pode-se usar um array para armazenar os nós da SegTree (considere que o array se chama st). O índice 0 é a raíz e os filhos da esquerda e direita do índice \(i\) são os índices \(2 \times i + 1\) e \(2 \times i + 2\), respectivamente.
A raiz da SegTree representa o segmento completo [0, n-1] do array A. Para cada segmento [L, R] armazenado no índice \(i\), onde L != R, o segmento é dividido no sub-segmento [L, (L+R)/2] (armazenado no índice \(2 \times i + 1\)) e sub-segmento [(L+R)/2 + 1, R] (armazenado no índice \(2 \times i + 2\)). Essa divisão continua até que o segmento tenha tamanho 1 (isto é, L == R), o que indica que chegou-se em um nó folha e, pela definição de SegTree, esse nó deve receber o valor correspondente de A, ou seja, st[i] = A[L] ou st[i] = A[R].
A função build abaixo ilustra o processo de construção de uma SegTree a partir do array A. Perceba que foi usada a função funcao para fazer a atualização dos nós da árvore. Nesse exemplo, a SegTree será responsável por realizar a soma dos elementos (RSQ).
A próxima função a ser analisada/implementada é a query, responsável por fazer as consultas. Ao analisar o nó \(i\), responsável pelo intervalo [tl, tr], como explicado na seção Atualizações, existem três possibilidades. O código abaixo mostra uma implementação da função query, ela recebe como parâmetros informações sobre o nó/segmento atual (ou seja, o índice \(i\) e os limites \(tl\) e \(tr\)) e também os limites da consulta, \(l\) e \(r\). Para fazer uma consulta no intervalo [l, r], a função deve ser chamada da seguinte forma: query(0, 0, n - 1, l, r), onde n representa o número de elementos de A.
A função update é responsável por fazer atualizações no array A e, consequentemente, na SegTree. O código abaixo mostra uma implementação da função update, ela recebe como parâmetros informações sobre o nó/segmento atual (ou seja, o índice \(no\) e os limites \(tl\) e \(tr\)), o índice \(i\) que se deseja atualizar e o novo valor a ser armazenado na posição \(i\). Para fazer A[i] = x, a função deve ser chamada da seguinte forma: update(0, 0, n - 1, i, x);, onde n representa o número de elementos de A.
O código abaixo mostra uma implementação completa de uma SegTree. Note que foi usado uma versão baseada em orientação à objetos, mas isso não é necessário.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 | |
Atualizações em Intervalos (Lazy Propagation)
Como visto, a função update atualiza apenas uma posição do array, mas em alguns casos é necessário alterar o valor de um intervalo do array, por exemplo, alterar os elementos da posição \(l\) a \(r\) para \(x\). Uma estratégia ingênua é chamar a função update para cada posição do array (complexidade \(O(n)\)). Note que se for necessário alterar todos os elementos do array, uma alternativa é alterar apenas a raiz e postergar a atualização dos outros nós. Dessa forma, os nós filhos são atualizados somente quando for realmente necessário. Esse processo é conhecido como Lazy Propagation. É importante destacar que, para implementar lazy propagation, cada tipo de SegTree vai requerer uma implementação um pouco diferente, por isso, será importante entender como essa estratégia funciona.
Na SegTree com Lazy Propagation, cada segmento (nó) terá também um valor lazy associado. Uma atualização dividirá o segmento da mesma forma feita anteriormente e definirá o valor lazy em cada segmento alcançado. Assim, sempre que um nó for analisado, seja por meio de uma atualização ou uma consulta, uma função, propagate, será chamada. Essa função fica responsável por atualizar a informação no segmento atual e passar o valor lazy para seus filhos.
Considere o problema de saber a soma dos elementos de um intervalo e que uma atualização de intervalo significa alterar o valor de todos os elementos do intervalo para um determinado valor. Para isso é necessário, além do vetor que armazena a SegTree, outros dois vetores: lazy e marked. O vetor lazy fica responsável por armazenar o valor do segmento que ainda não foi propagado para os nós filhos. Já o vetor marked (vetor booleano) indica se há uma atualização para ser feita no nó.
A função de propagação (propagate) é a função que atualiza o valor de um nó e posterga a atualização para os filhos. Essa função deve ser chamada toda vez que um nó for analisado (seja por uma atualização ou uma consulta). O código abaixo ilustra essa função.
- Parâmetros:
p: nó atualL: limite inferior do intervalo queprepresenta (inclusivo)R: limite superior do intervalo queprepresenta (inclusivo)
A função abaixo altera o valor dos elementos do intervalo [l, r] para novoValor.
- Parâmetros:
no: nó atualtl: limite inferior do intervalo quenorepresenta (inclusivo)tr: limite superior do intervalo quenorepresenta (inclusivo)l: limite inferior do intervalo que se deseja atualizar no vetorr: limite superior do intervalo que se deseja atualizar no vetornovoValor: novo valor dos elementos no intervalo
Versão final da classe SegTree com alguns exemplos de utilização:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 | |
Material complementar
- ⭐️ Segment Tree, part 1 (ITMO Academy) 🤯
- ⭐️ Segment Tree, part 2 (ITMO Academy) 🤯
- ⭐️ Segment Tree
- ⭐️ Segment Tree (Árvore de Segmentos)
- ⭐️ Segment Tree com Lazy Propagation
- Segment Tree (CS Academy)
- Segment Trees
- Segment Tree - VisuAlgo
- Segment Tree Data Structure - Min Max Queries
Disjoint Set Union (DSU)
Para entender DSU, considere o seguinte problema (extraído desse link): suponha que exista um grupo de \(N\) amigos em um jogo. Inicialmente, cada um deles joga contra todos os outros. Conforme o jogo avança, alianças são formadas entre eles. A relação de aliança é transitiva, o que significa que se \(A\) e \(B\) são aliados e \(B\) e \(C\) são aliados, então \(A\) e \(C\) também são aliados. Você sabe quando as alianças são formadas. Em certos momentos você precisa saber se dois amigos em particular estão no mesmo time ou não.
Uma estratégia natural seria construir um grafo e, a cada atualização, incluir uma nova aresta ligando dois vertices do grafo. Para cada consulta pode-se realizar um percurso no grafo (usando Busca em Largura ou Busca em Profundidade) começando no nó \(A\) e verificando se o nó \(B\) é visitado. Adicionar uma aresta é muito rápido, mas as consultas são lentas. Uma estratégia mais eficiente para resolver esse problema é usar Disjoint Set Union.
Um conjunto disjunto, também chamado union-find, é uma estrutura de dados que opera com um conjunto particionado em vários subconjuntos disjuntos. As duas principais operações dessa estrutura são:
find: Dado um elemento particular do conjunto, a função identifica o subconjunto do elemento. Para isso, a função retorna o representante do conjunto.join: Une dois subconjuntos em um único subconjunto.
Um conjunto disjunto funciona representando cada componente conectado como uma árvore, onde a raiz de cada árvore é o representante do componente. O pai de cada nó é outro nó no mesmo componente. Considere o exemplo dos amigos jogando para ver como a estrutura funciona. Suponha que existam 6 amigos jogando. Inicialmente, não há alianças, então cada nó é a raiz de uma árvore (os amigos são numerados de 0 a 5):
Em seguida, suponha que 1 e 3 se tornem aliados. Considere que o nó 1 seja escolhido como representante:
Então 2 e 4 se tornam aliados:
Os amigos 0 e 5 são os próximos. Considere que 5 seja escolhido como representante:
Finalmente, uma aliança é formada entre 4 e 3. Nesse caso, é preciso pegar a raiz de uma árvore e anexá-la como filho da raiz da outra árvore:
Implementação
A estrutura DSU pode ser implementada usando arrays. Na implementação a seguir, o array pai contém para cada elemento o próximo elemento do encadeamento ou o próprio elemento se ele for um representante. Inicialmente, cada elemento pertence a um conjunto distinto:
A função find retorna o representante do elemento x. O representante pode ser encontrado seguindo o encadeamento que começa em x. O código abaixo ilustra essa operação, note que a complexidade da função é \(O(n)\):
Otimizações do Union-Find
A primeira otimização do algoritmo, conhecida como Path Compression, está na busca do representante de um elemento, ou seja, na função find. Observe que se a função find for eficiente, a função join também se torna eficiente. Note que o que gasta tempo na função são as chamadas recursivas da função que precisam passar por todos os ancestrais de um determinado elemento. Porém, pode-se usar um princípio da Programação Dinâmica: evitar o recálculo! Uma vez que calculado o representante de um elemento x (ou seja, find(x)), pode-se salvá-lo diretamente como seu pai (pai[x]=find(x);). Assim, nas próximas vezes que for calculado o valor de find(x), a função retornará seu representante rapidamente, pois ele já estará salvo em pai[x], o que evita a necessidade de percorrer todos os ancestrais que estavam entre x e o representante. Para fazer essa otimização basta que, na hora de o valor de find(x) for retornado, o mesmo seja salvo em pai[x]. Segue a implementação da função find otimizada:
Outra otimizaçao, conhecida como Union by size, altera a forma como é feita a união dos conjuntos. Na primeira implementação da função join, o segundo conjunto sempre é anexado ao primeiro, o que pode levar a árvores degeneradas. Nessa otimização, o menor conjunto (menor número de elementos) é unido ao maior conjunto. Segue a implementação da função join otimizada: