Estrutura de Dados e STL1
Estrutura de dados (ED) é a forma como os dados são armazenados na memória do computador com o objetivo de tornar o processamento mais fácil e eficiente. Cada uma possui suas próprias vantagens e desvantagens, por isso, é crucial conhecer diferentes estruturas de dados (básicas e avançadas) para conseguir definir qual as mais apropriada para um determinado problema. Em programação competitiva, com o objetivo de economizar uma grande quantidade de tempo ao implementar um algoritmo, também é muito importante saber quais EDs estão disponíveis na biblioteca padrão, como usá-las e qual a complexidade de cada operação da ED.
A seguir são apresentados as estruturas de dados presentes na biblioteca padrão do C++ comumente usadas em competições.
Leitura recomendada:
- C++ Standard Library Containers
- More Operations on Sorted Sets
- C++ Sets with Custom Comparators
- C++ Containers library
vector
Um vector é um array dinâmico que permite adicionar e remover elementos de forma eficiente no final da estrutura. Por exemplo, o código a seguir cria um vetor vazio e adiciona três elementos a ele:
Observe que os elementos são inseridos no fim. Então, os elementos podem ser acessados como em um array comum:
Outra maneira de criar um vetor é fornecer uma lista de seus elementos:
Também pode-se fornecer o número de elementos e seus valores iniciais:
A função size() retorna o número de elementos no vector. Por exemplo:
Uma alternativa mais simples é a seguinte:
A função back retorna o último elemento de um vetor e a função pop_back remove o último elemento:
A figura abaixo mostra mais operações e uso do vector.

Complemente sua leitura e seu conhecimento:
deque
Um deque é um array dinâmico que pode ser manipulado eficientemente em ambas as extremidades da estrutura. Como um vector, um deque fornece as funções push_back e pop_back, mas também fornece as funções push_front e pop_front que não estão disponíveis em um vector. veja uma exemplo:
As principais funções da deque são:
push_front(x): adiciona o elementoxno início da estrutura;push_back(x): adiciona o elementoxno fim da estrutura;pop_front(): remove o primeiro elemento da estrutura;pop_back(): remove o último elemento da estrutura;front(): retorna o primeiro elemento da estrutura;back(): retorna o último elemento da estrutura;size(): retorna o número de elementos da estrutura.
O código a seguir ilustra a utilização da estrutura:
As operações de um deque funcionam em tempo médio \(O(1)\). A figura abaixo mostra mais operações e uso do deque.

Complemente sua leitura e seu conhecimento:
queue
A estrutura da queue (fila) corresponde a uma fila simples da vida real e segue a regra First In First Out (FIFO). Suas principais operações são: inserir um elemento no fim da fila, acessar e remover o primeiro elemento da fila. Essas operações possuem complexidade em \(O(1)\).
As principais funções da queue são:
push(x): adiciona o elementoxno fim da fila;pop(): remove o primeiro elemento da fila;front(): retorna o primeiro elemento da fila;size(): retorna o número de elementos da fila.
O código a seguir ilustra a utilização da estrutura:
Complemente sua leitura e seu conhecimento:
stack
Uma stack (pilha) é uma estrutura muito semelhante a uma fila, mas que segue a regra Last In First Out (LIFO). Ou seja, ao inserir um elemento na pilha, ele é adicionado no topo e esse é o elemento que se tem acesso. Suas principais operações são: inserir um elemento no topo da pilha, acessar e remover o elemento do topo da pilha. Essas operações possuem complexidade em \(O(1)\).
As principais funções da stack são:
push(x): adiciona o elementoxno topo da pilha;pop(): remove o elemento do topo da pilha;top(): retorna o elemento do topo da pilha;size(): retorna o número de elementos da pilha.
Veja um exemplo de utilização da estrutura:
Complemente sua leitura e seu conhecimento:
priority_queue
Uma fila de prioridade (priority_queue) é uma estrutura semelhante a uma fila ou pilha, mas ao invés de inserções e remoções acontecerem em uma das extremidades da estrutura, o maior (ou menor) elemento é sempre retornado durante o acesso/remoção. Inserções e remoções possuem complexidade \(O(\log n)\) e o acesso ao elemento de maior prioridade é \(O(1)\). Uma fila de prioridade geralmente é implementada usando uma estrutura chamada heap que é muito mais simples do que uma árvore binária balanceada usado em um set.
As principais funções da priority_queue são:
push(x): adiciona o elementoxna fila de prioridade;pop(): remove o elemento de maior prioridade;top(): retorna o elemento de maior prioridade;size(): retorna o número de elementos da fila de prioridade.
O código a seguir ilustra a utilização da estrutura:
Se for necessário criar uma fila de prioridade que suporte encontrar e remover o menor elemento, pode-se fazer da seguinte forma:
- Note o uso da função de comparação
cmp. Essa função deve receber dois argumentos do tipo armazenado na fila de prioridade e retornatruese o primeiro for considerado menor que o segundo.
Para o exemplo anterior, outra alternativa é usar a função greater:
Complemente sua leitura e seu conhecimento:
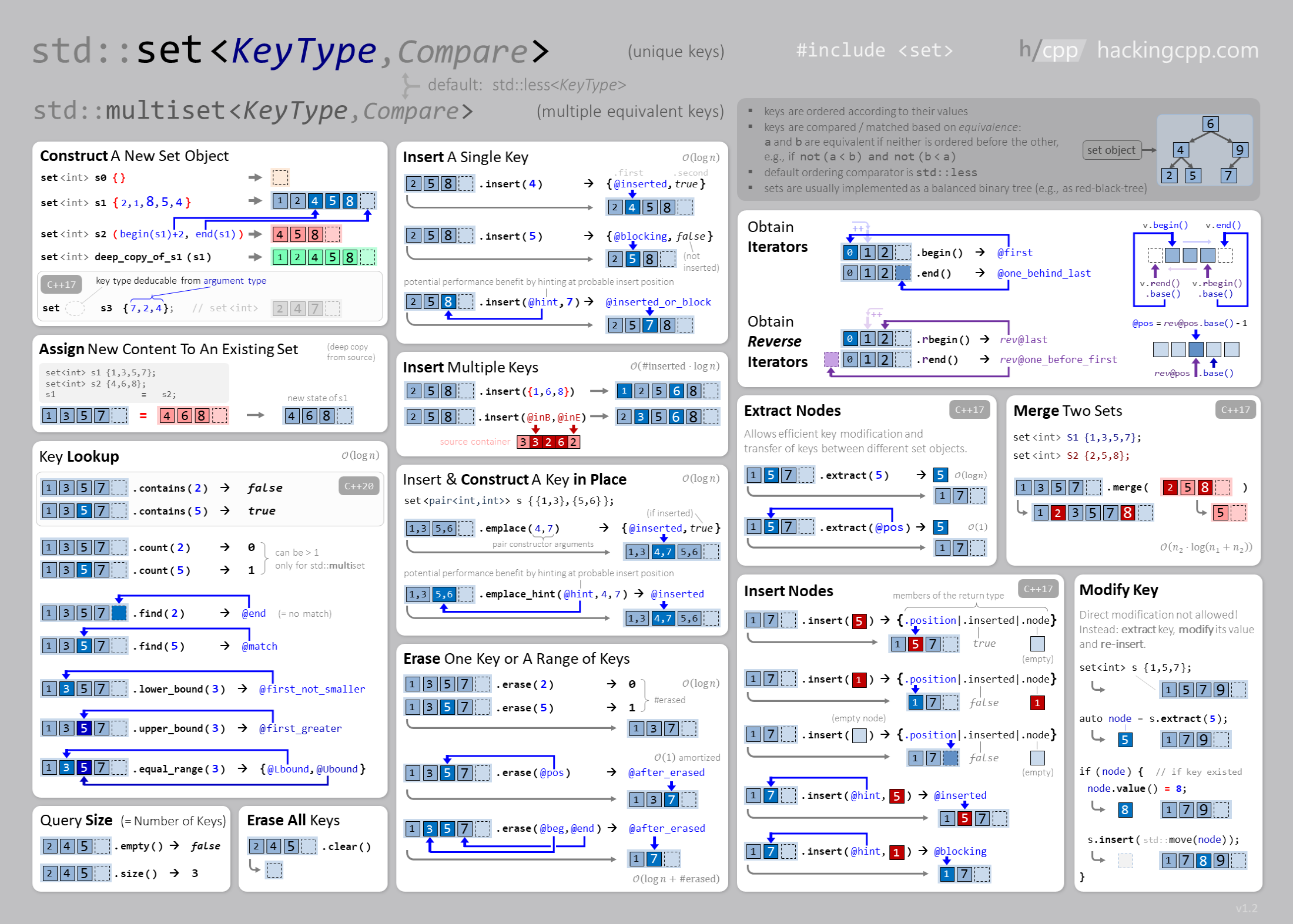
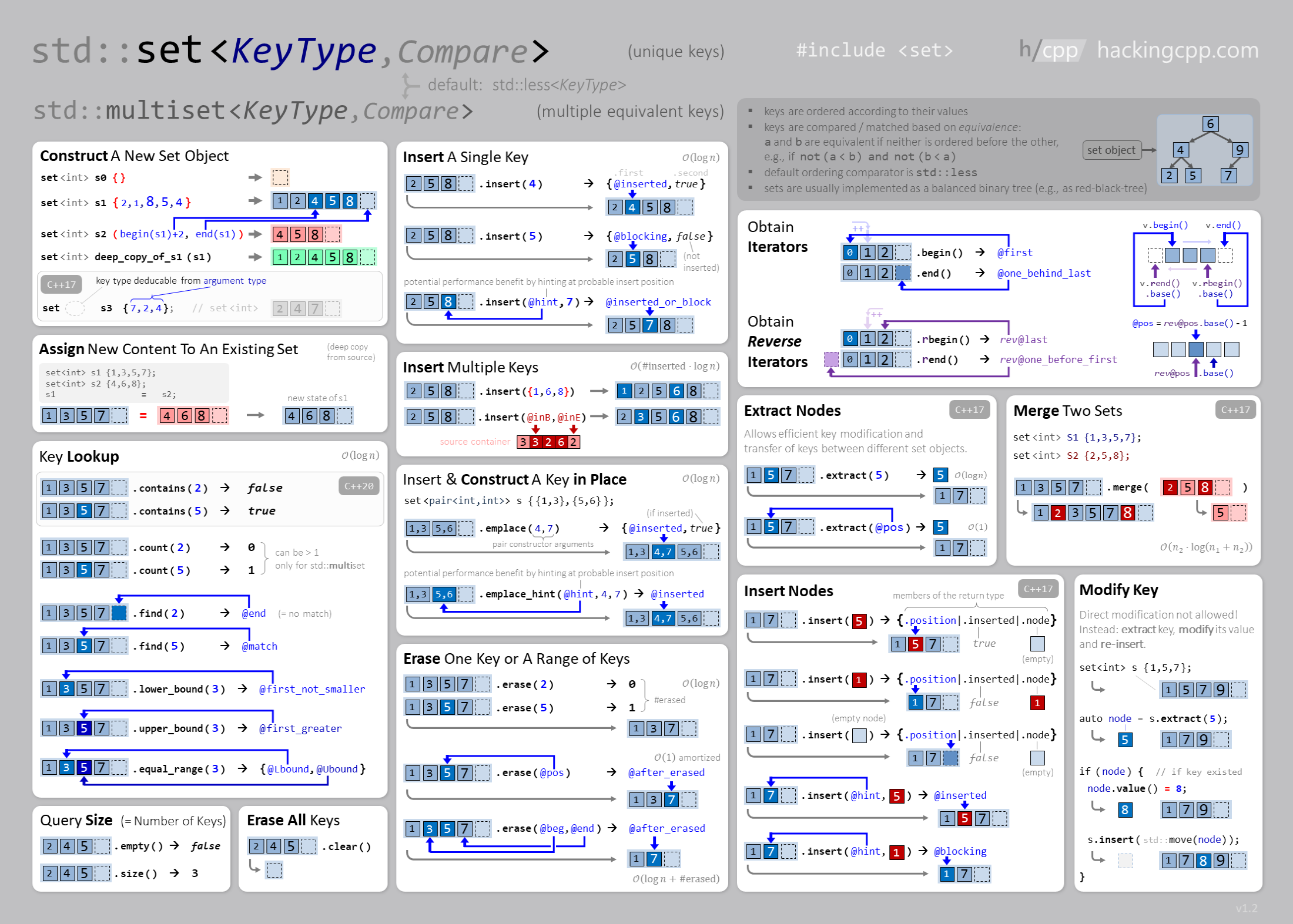
set e multiset
Semelhante a um conjunto matemático, um set é uma coleção de elementos únicos, ou seja, todos os seus elementos são distintos. A estrutura é baseada em uma árvore binária balanceada (red-black tree) e acessar seus elementos é \(O(\log n)\). Consequentemente, não é possível acessar os elementos do set usando o operador [], como acontece em um vector. Além disso, os elementos são mantidos ordenados.
As principais funções do set (e multiset) são:
insert(x): adiciona o elementoxno conjunto. Se ele já estiver no conjunto, nada é feito;erase(x): remove o elementox;count(x): retorna o número de elemento cuja chave sejax;find(x): retorna um iterador para o elemento com chavex;size(): retorna o número de elementos do conjunto.
O código a seguir ilustra a utilização da estrutura set:
- Como
end()aponta para um elemento após o último elemento, deve-se diminuir o iterador em uma unidade. - Lembre-se que em um
settodos seus elementos são distintos. Assim, a funçãocountsempre retornar ou 0 (elemento não está noset) ou 1 (o elemento está noset).
A estrutura set também fornece as funções lower_bound(x) e upper_bound(x) que retornam um iterador para o menor elemento em um set cujo valor é pelo menos ou maior que x, respectivamente. Em ambas as funções, se o elemento solicitado não existir, o valor de retorno é end().
Um multiset é um conjunto que pode conter várias cópias do mesmo elemento. Por exemplo, o código abaixo adiciona três cópias do valor 5 ao multiset:
A função erase remove todas as cópias de um valor do multiset:
Caso seja necessário remover apenas uma cópia, pode-se fazer da seguinte forma:
A figura abaixo mostra mais operações e uso do set e multiset.
{kind=link}
Complemente sua leitura e seu conhecimento:
- Standard Associative Containers
- Set in C++ Standard Template Library (STL)
- Multiset in C++ Standard Template Library (STL)
- std::set
- std::multiset
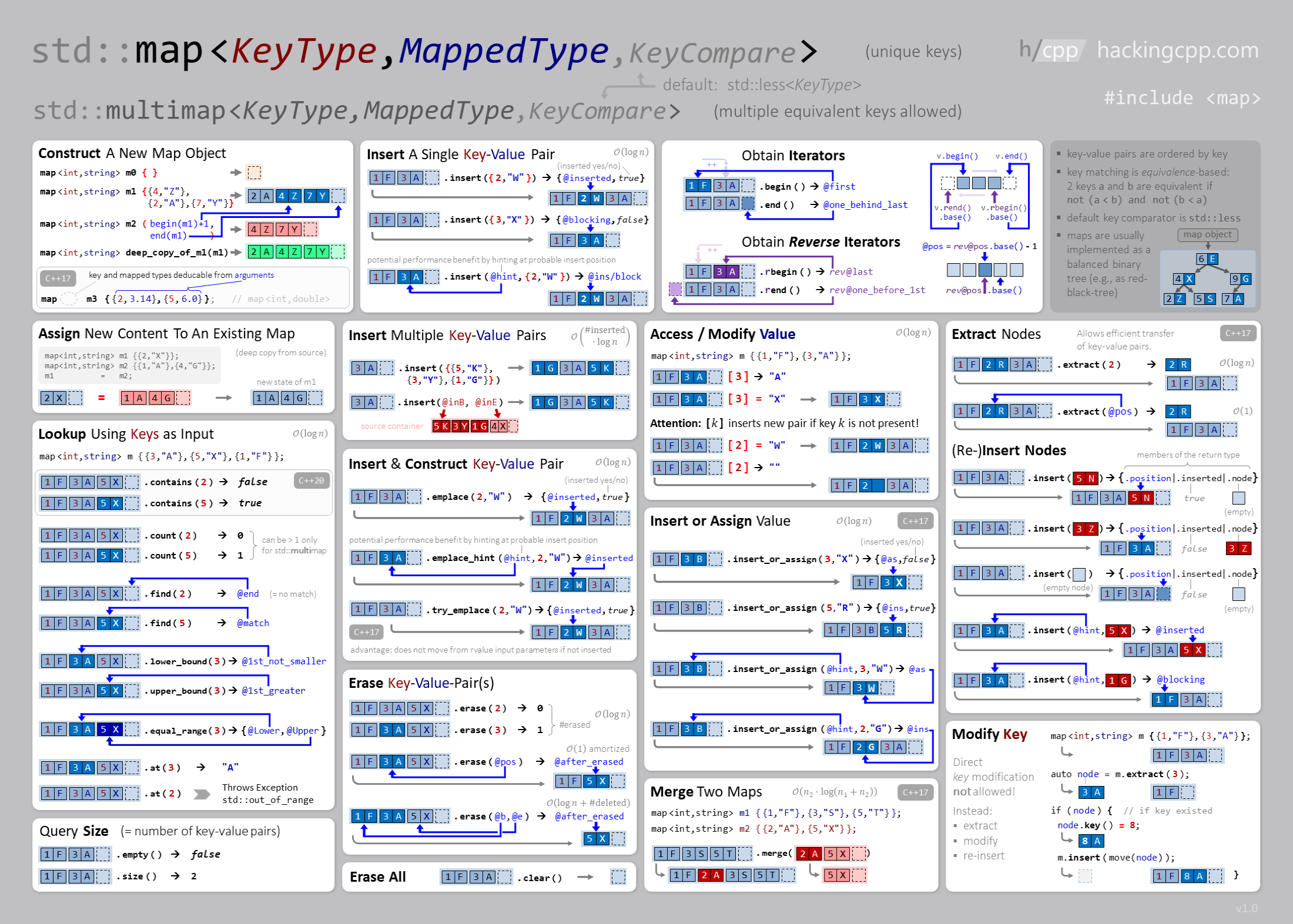
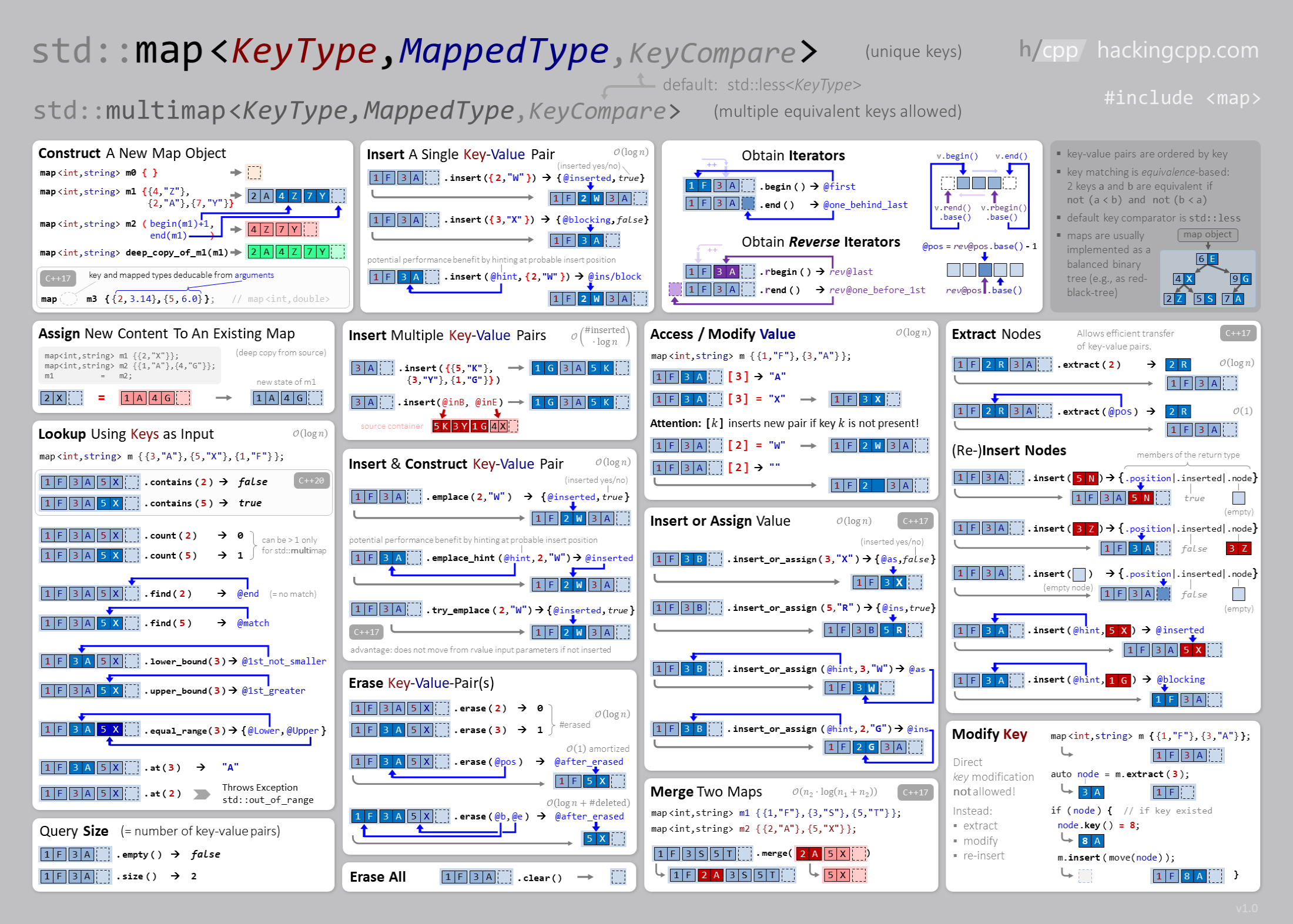
map e multimap
Um map é um conjunto que consiste em pares de valores-chave. Um map também pode ser visto como um array comum. Enquanto as chaves em um array são sempre inteiros consecutivos \(0, 1, \dots , n − 1\), onde \(n\) é o tamanho do array, as chaves em um map podem ser de qualquer tipo de dados e não precisam ser valores consecutivos. Como no set, o map é baseado em em uma árvore binária balanceada (red-black tree) e acessar seus elementos é \(O(\log n)\).
O código a seguir cria um map cujas chaves são strings e os valores são int:
Se o valor de uma chave for solicitado, mas que não existe no map, a chave será adicionada automaticamente ao map com um valor padrão do tipo (se for uma classe o construtor padrão é chamado). Por exemplo, no código a seguir, a chave "Ana" com valor 0 é adicionada aomap.
Veja mais alguns exemplos de utilização da estrutura:
A figura abaixo mostra mais operações e uso do map e multimap.
{kind=link}
Complemente sua leitura e seu conhecimento:
- Standard Associative Containers
- Map in C++ Standard Template Library (STL)
- Multimap in C++ Standard Template Library (STL)
- std::map
- std::multimap
unordered_set e unordered_multiset
Um unordered_set é um contêiner associativo que contém um conjunto de objetos exclusivos. Já um unordered_multiset permite cópia dos elementos. Ambas as estruturas são baseadas em tabela hash e suas operações possuem complexidade, em média, em tempo \(O(1)\). Internamente, os elementos não seguem nenhuma ordem. Veja um exemplo de uso das estruturas:
A figura abaixo mostra mais operações e uso do unordered_set e unordered_multiset.

{kind=link}
Complemente sua leitura e seu conhecimento:
unordered_map e unordered_multimap
é um conjunto que consiste em pares de valores-chave
Um unordered_map é um contêiner associativo que contém pares de valores-chave com chaves exclusivas. Já um unordered_multimap permite múltiplas cópias das chaves. Ambas as estruturas são baseadas em tabela hash e suas operações possuem complexidade, em média, em tempo \(O(1)\). Internamente, os elementos não seguem nenhuma ordem. Veja um exemplo de uso das estruturas:
- Não é possível usar o
operator[]como nomapeunordered_map.
A figura abaixo mostra mais operações e uso do unordered_map e unordered_multimap.

{kind=link}
Complemente sua leitura e seu conhecimento: